クロールバジェットとは?クロールを効率化する対策方法について解説

クロールバジェットとは、検索エンジンのクローラーがサイトをクロールできる上限を指します。クロールバジェットを管理しなければ、重要なページがインデックスされなくなることがあったり、新しいコンテンツの反映が遅れる可能性があるなど、SEOに悪影響を及ぼすかもしれません。ただし、基本的にクロールバジェットを気にする必要があるのは、サイトのページ数が最低でも1万を超えるような場合という点には、あらかじめ留意しておきましょう。
クロールバジェットを阻害する要因は、絞り込みによる検索結果ページ、URLパラメータによる重複ページ、ソフト404エラーページといったような不要なページ群が挙げられます。このようなクロールバジェットを最適化するためには、重複コンテンツの統合やURL正規化、クロールのブロック、リダイレクトチェーンの解消など、適切な対策が必要不可欠です。
本記事では、クロールバジェットの基本から、影響を及ぼすような要因、対策方法について解説します。また、クロールバジェットに関するよくある質問についてもまとめています。クロールバジェットの最適化で、SEOパフォーマンス向上につなげましょう。
目次
クロールバジェットとは?
クロールバジェットとは、検索エンジンのクローラーが、クロール(Webページの情報を収集すること)できる上限です。インターネット上のサイトやページは常に増加し続けていることもあり、そのすべてをクローラーが巡回するには限界があります。当然、ひとつのサイトに割り当てられたクロールのための活動量(時間とリソース)も限られており、その活動量をクロールバジェットと呼びます。おもに、Google検索において用いられる用語です。
クロールが限られるということは、クロールされないページが発生する可能性があることを示唆します。言い換えれば、インデックスされるページ数にも影響を及ぼすため、クロールバジェットはSEOにおいて留意すべき事柄だと言えるでしょう。ただし、後述するようにクロールバジェットに留意すべきなのは一部のサイトに限られます。
なお、Google検索セントラルによると、クロールの割り当ては「Googlebotによるクロールが可能であり、かつクロールが必要なURLの数」であると定義されています 。
クロールバジェットを考慮すべきWebサイトとは
クロールバジェットは、中規模〜大規模なサイトで意識する必要があります。Googleは公式サイトでクロールバジェットを管理すべき対象として次のようなサイトを挙げています。
- 大規模(重複のないページが 100 万以上)で、コンテンツが中程度に(1 週間に 1 回)更新されるサイト
- 中規模以上(重複のないページが 1 万以上)で、コンテンツがかなり頻繁に(毎日)更新されるサイト
- Search Console で URL の大部分が「検出- インデックス未登録」に分類されるサイト
引用:大規模なサイト所有者向けのクロール バジェット管理ガイド
「検出- インデックス未登録」とはGoogleサーチコンソールでレポートされる指標の一つです。Googlebotにページは発見されているものの、クロールされていないページが当てはまります。
上記からもわかる通り、ページ数が数百から数千程度で、サイトの更新頻度があまり高くなく、ページ公開と同日にクロールされているようなサイトはクロールバジェットを意識する必要はありません。サイトマップを最新の情報にし、定期的にインデックスカバレッジ(各ページのインデックス状況の確認)をすれば良いでしょう。
クロールバジェットの対象
Googlebotがクロール可能な一般的なURLはもちろんのこと、AMPやhreflang、モバイル専用URLといった代替URL、CSSやJavascriptといった埋め込みコンテンツなどもクロールバジェットの割り当て対象になります。
小規模サイトが気にするべきものではありませんが、中規模~大規模のサイトは念のため把握しておきましょう。
クロールバジェットに影響する要因【Google公式見解】
Googleはクロールバジェットに影響する要因をいくつか公表しています。次のような価値の低いページでは、サーバーのリソースが浪費され、本当に価値のあるページのクロールが妨げられる可能性があることをGoogleは指摘しています。
Googleが指定する価値の低いページを、その重要度順に示します。
- 絞り込みによる検索結果ページ
- URLパラメータによる重複ページ
- ソフト404エラーページ
- 無限にリロードできるページ
- ハッキングされたページ
- 質の低いコンテンツやスパムコンテンツ
絞り込みによる検索結果ページ
絞り込み検索結果ページは、ユーザーの絞り込み条件によって生成される動的なページです(ファセットナビゲーションとも呼ばれます)。例えば、ECサイトで「価格」「ブランド」「カラー」などで絞り込み検索をすると、異なるページがいくつも生成されます。
こうしたページはそれぞれがすべてクロールの割り当て対象になります。つまりクロールバジェットを著しく浪費するため、適切に管理しないと、クローラーが重要なページにたどり着く前にリソースを使い果たすかもしれません。
URLパラメータによる重複ページ
ユーザー情報や追跡情報がURLパラメータ(URL末尾に加えられた変数)によって保存されることで、ページの内容が同じでも異なるURLが生成されることがあります。いわゆる重複コンテンツです。
例えば、「sort=price」と「sort=popularity」のように、同じ商品のリストを異なる順序で表示するだけのページがいくつも存在すると、クローラーはこれらを別々のページとして扱います。クロールバジェットが無駄に消費される可能性が高いでしょう。
ソフト404エラーページ
ソフト404エラーページとは、実在しないページがあたかも存在しているかのように、クローラーに誤認されるエラーです。ページが存在しないことから404エラーとページ上に表示されながらも、正常に読み込まれていることを示すステータスコード200が返されることをソフト404といいます。
ステータスコードが200の場合、Googlebotは通常通りクロールすることになります。つまり存在しないページをクロールしていることになるため、クロールバジェットの無駄遣いとなるでしょう。また、ページの中身がないと判断されて、低品質なコンテンツという評価を受けるおそれがあります。
ステータスコードとは
ステータスコードとは、クライアント(クローラーやブラウザなど)のリクエストに対するWebサーバーからのHTTPレスポンスに含まれる「3桁の数字」を指します。リクエストの結果(成功、失敗、リダイレクト有無など)を端的に伝えたり、問題がどこに発生しているか特定する手がかりとしての役割を持ちます。
無限にリロードできるページ
無限にリロードできるページとは、例えば「翌月」のリンクがあるカレンダーなど、半永久的にたどり続けられるページです。これらに対しGoogleは「infinite space(無限の空間)」と呼んでいます。
先ほどの絞り込みによる検索結果も、無限の空間に該当します。限りなくページが生まれることから、当然ですがクロールバジェットを消費することになります。
ハッキングされたページ
ハッキングされたページとは、セキュリティ上の脆弱性を攻撃され、サイト運営者の許可なくコンテンツが配置されたページです。ユーザーの役に立たない低品質なコンテンツが追加され、クロールバジェットの浪費につながるだけでなく、サイト全体のSEO評価を下げるリスクが伴います。
質の低いコンテンツやスパムコンテンツ
ユーザーの検索意図からズレており、なんら有益な情報がないコンテンツも、クロールバジェットを削り、サイト全体の評価を下げる要因のひとつです。
例えば、キーワードの乱用やコメントスパム、コピーコンテンツなどが低品質コンテンツに該当します。
クロールバジェットの対策方法は?
クロールバジェットを無駄に消費せず、効率的にクロールしてもらえるようにする方法について解説します。
Googleはクロールバジェットを増やす方法を次のように示しています。
Google では、人気、ユーザー価値、一意性、配信容量に基づいて、各サイトに対するクロールリソースの量を決定します。クロールバジェットを増やす唯一の方法は、クロールの処理能力を高めること、そして何よりも検索ユーザーにとってのサイトコンテンツの価値を高めることです
引用:大規模なサイト所有者向けのクロール バジェット管理ガイド
具体的に、どのように改善すれば良いのかもう少しかみ砕いて解説します。
クロール状態にエラーが出ていないか確認する
クロールエラーがあると、クローラーがサイト内のページを正しくクロールできず、クロールバジェットを効率よく使えません。クロールバジェット対策の基本的な対策の一つが、このクロールエラーの解消です。
サーチコンソールでクロールエラーを定期的に確認し、対応しましょう。サーチコンソールにログイン後、「クロールの統計情報⇒ホストのステータス」でクロールエラーの数や理由を確認できます(以下の画像を参照)。
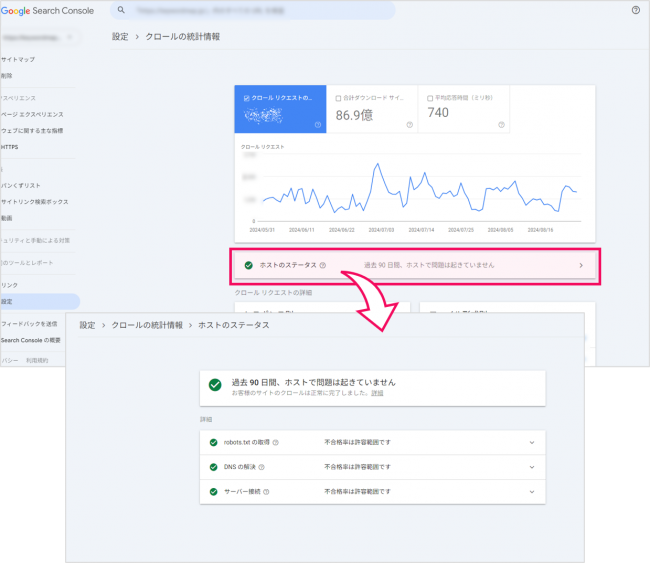
基本的にはGooglebotがクロールした際に、エラーを返すページの修正を行うことで、クロールバジェットの最適化を図ります。なお、エラーに関してはGoogle公式ページ「クロールの統計情報レポート」の「クロール レスポンス」に具体例が掲載されていますので参考にしてみてください。
重複コンテンツを統合する
重複コンテンツを一つにまとめることで、クローラーの効率を高められます。URLの正規化(canonicalの使用)やリダイレクト処理で、重複コンテンツを統合しましょう。
canonicalとは、クローラーにどのページが正規ページであるかを示すための設定です。検索結果に表示させるURLを指定し、ページ評価の分散を防ぐことにもつながります。HTMLファイルheadタグ内に、canonicalを記述することで設定できます。
また、リダイレクトとはユーザーや検索エンジンが、あるWebページに訪問した際に自動で別のページに転送される仕組みのことです。canonicalと同じく、重複コンテンツによって分散されたSEO評価を一つのページに集約させることができます。
robots.txtを使用してクロールをブロックする
robots.txt(ロボットテキスト)で、クロールしてほしくないページに対してクロールの巡回を拒否することができます。絞り込みによる検索結果ページや無限にリロードできるページなど、ユーザーには必要だとしても、クロールの対象外にしたいページを設定しましょう。無駄なクロールを防いで、クロールバジェットの浪費を防ぐことができます。
robots.txtとは、ルートディレクトリ(TOPページのある最上位の構造)に設置するテキストファイルです。メモ帳などのファイル名を「robots.txt」とし、ルートディレクトリにファイルをアップし、内容を記述しましょう。
また、Google の Gary Illyes(ゲイリー・イリース)氏曰く、アクションURL(フォームを送信する、カートに商品を追加する、といったアクションに関するURL)へのクロールも、robots.txtで制御することでクロール過多を防げると推奨しています。ECサイトや大規模ポータルサイトを運営している場合は留意するようにしましょう。
削除したページには404もしくは410のステータスコードを設定する
削除したページに対して、正確な404または410ステータスコードを設定することで、ソフト404エラーを防ぐことができます。
404エラーは、ページが存在しないことを示すステータスコードです。一方、410エラーはページが永久に削除されたことを示します。特に410エラーを使用することで、クローラーが再クロールを試みる頻度を減らせます。
正しく404エラーページを設定することで、404ステータスコードも正しく返すことができます。設定方法は以下の参考記事を参考にしてみてください。

XMLサイトマップを最新の状態に保つ
XMLサイトマップ(sitemap.xml)とは、クローラーにサイトの全体像や構造、ページ情報などを理解させるためにXML形式で出力されたファイルです。XMLサイトマップは常に最新の状態に保ち、クロールさせたいページをリスト化してすべて含めましょう。また、追加したコンテンツには、lastmodタグ(最終更新日を記載する要素)を記述することも推奨されています。
XMLサイトマップを作成するには、自動生成ツールや拡張機能での記述や、WordPressプラグインでの生成、Google推奨のフォーマットへの記述といった方法が挙げられます。

リダイレクトチェーンを解消する
リダイレクトチェーンとは、複数ページをまたぐリダイレクト処理です。つまりリダイレクトが数珠つなぎで何度も繰り返されることを指します。当然、クローラーが転送され続けるURLを巡回していくので、クロールバジェットを無意味に消費してしまいます。
リダイレクトチェーンを解消するためには、不要なリダイレクトを削除し、リダイレクト回数を最小限に抑えることが大切です。理想としては、1つのリダイレクトで目的のページに到達することが望ましいですが、最大でも5回以内に抑えるのがよいでしょう※。リダイレクトチェーンが長すぎると、インデックスできずにサーチコンソール状にエラーが表示されます。
※参考:【SEOクイズ】リダイレクトチェーンは何回まで許容される?【SEO情報まとめ】
ページの読み込み速度を改善する
ページの読み込み速度が速いと、クローラーが効率よくサイトをクロールできます。サーバーがすばやく応答し、ページが高速でレンダリング(コードをWebページで見られる状態に変換)されることで、クロールの処理能力を促進し、クロールバジェットを増やすことにつながります。
ページの読み込み速度を改善するための施策は、以下の通りです。
- テキストファイルの圧縮(gzipやdeflateを使用してファイルサイズを削減)
- 画像・動画の最適化(適切なサイズ、フォーマット使用、レスポンシブ対応)
- 不要な外部ファイルの削除(使用していないCSSやJavaScriptの削除)
- ブラウザキャッシュの有効期限設定
- 画像の遅延読み込み実装(スクロールに応じて画像を読み込む)
詳しくは以下の記事で解説しています。あわせて参考にしてみてください。

クロールバジェットに関するよくある質問
自社サイトにいつクローラーが巡回しに来たのか確認する方法など、クロールバジェットに関してよく挙がる質問について回答とともにみていきましょう。
Googleクローラーがいつ来たか確認する方法はありますか?
クローラーの来訪を確認する方法はいくつかありますが、Googleサーチコンソールを使用することが一般的です。
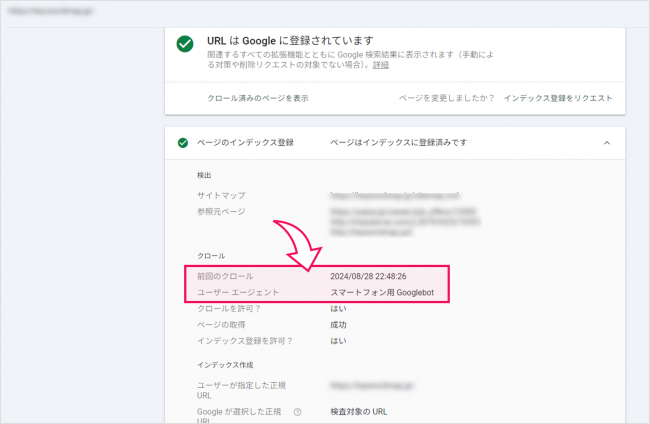
サーチコンソールでは、クローラーが最後にサイト・ページをクロールした日時を確認できます。サーチコンソールの「URL検査ツール」で、確認したいページのURLを入力すると、「ページのインデックス登録」欄に前回のクロール日時が表示されます(以下の画像を参照)。
サイトへのクロール頻度は調整できますか?
所有サイトであれば、Googlebot にクロールされる回数を減らすことが可能です。ただし、よほどの理由がない限りクロールの頻度を減らすことは推奨されていません。そのデメリットについて、Googleは次のように述べています。
警告: Googlebot のクロール頻度の低減を検討する場合は、その影響が広範囲に及ぶことにご留意ください。たとえば、Googlebot が検出できる新規ページの数が少なくなる、既存ページについて更新される頻度が低くなる(その結果、価格や商品の在庫状況が検索に反映されるまでの時間が長くなる)、削除済みページがインデックスに残る時間が長くなる、といった影響が考えられます。
引用:Googlebot のクロール頻度を下げる
上記を前提としたうえで、クロール頻度を下げる方法はGoogleのクロールリクエストに対し、通常の200ステータスコードの代わりに、500、503、または429のステータスコードを返すことが挙げられます。
ただし、これは短期間(1〜2日程度)の間だけクロール頻度を下げるために推奨される方法です。上記のステータスコードが長期的にわたって返されると、URLがインデックスから削除される可能性があるので注意が必要です。
クロール頻度はSEOのランキング要因ですか?
クロール頻度はランキングの要因(シグナル)ではありません。Googleのアルゴリズムでは、何百ものシグナルを活用しており、クロール頻度が高いこと自体がランキングに直接影響するわけではありません。
頻繁にクロールされるサイトは、更新情報が早く検索エンジンに反映されやすくなりますが、それが直接的にSEOランキングに影響するわけではないことを理解しておく必要があります。
nofollowの設定はクロールバジェットに影響しますか?
nofollowの設定はクロールバジェットに影響を与えます。nofollowは、他ページのリンクをクロールしないように指示するためのものです。クローラーが無駄にクロールするページを減らし、クロールバジェットを効率化できます。

まとめ:クロールバジェットを最適化してインデックスの効率を向上させよう
本記事では、クロールバジェットについて解説しました。クロールバジェットとは、検索エンジンのクローラーがサイトをクロールできる上限で、特に中規模以上のサイトで重要です。
クロールバジェットを最適化するためには、以下の方法があります。
- クロールエラーの確認と修正
- 重複コンテンツの統合
- robots.txtによるクロールのブロック
- 削除ページへの404もしくは410設定
- XMLサイトマップの最新化
- リダイレクトチェーンの解消
- ページ読み込み速度の改善
対策を実施することで、クロールの効率を高め、重要なページが正しくインデックスできるようになります。ただし、クロールバジェットの最適化は一度で終わるものではありません。定期的にサイトの状態を確認し、必要に応じて対策を講じることが重要です。
詳しくはこちら










Keywordmapのカスタマーレビュー
ツールは使いやすく、コンサルタントのサポートが手厚い
良いポイント
初心者でも確実な成果につながります。サポートも充実!
良いポイント
機能が豊富で、ユーザーニーズ調査から競合分析まで使える
良いポイント