robots.txtの書き方や設定方法、自社サイトにおけるSEO効果について”無料”で相談してみませんか?
他にも、貴社に最適なテクニカルSEO対策・コンテンツSEO対策・リスティング広告運用を無料でアドバイスいたします!
▶無料のSEO相談窓口はこちらから
robots.txtとは?書き方や使用する目的、SEO効果について解説

この記事ではrobots.txtの目的や準備の仕方、正しい書き方、設置・確認方法などを解説します。SEO対策を進めていくと必要になる場合もありますので、ぜひ参考にしてください。
また、Keywordmapを開発したCINCでは、ビッグデータを活用し、SEO戦略の策定から効果検証まで一気通貫で支援しています。SEOに詳しい人がいない、SEOの成果が出ないとお困りの方はお気軽にご相談ください。⇒CINCのSEOコンサルティング・SEO対策代行サービス
目次
robots.txtとは
robots.txt(ロボッツテキスト)は、Webサイトのルートディレクトリ(ファイル構造の最上階層のディレクトリ)に設置するテキストファイルで、主な働きは次の2点です。
- Webサイトの指定したURL(ページ)に対し、検索エンジンのクロールを禁止する(Webサイトのクロール最適化につながりSEO効果が期待できます。)
- リソースを軽減するため画像やCSS、JavaScriptなどのファイルへのクロールを禁止する
別の言い方をすれば、検索エンジンのクローラーがWebサイトのどのURLを巡回してよいのか伝えるのがrobots.txtの役割になります。なおrobots.txtは、クロールを禁止するだけでなく、許可する機能も持ち合わせています。
詳しくは後述しますが、設定方法はごくごく簡単に説明すると次の通りです。
- robots.txtファイルにクロールを制限(禁止)する構文を記述する
- ドメインのルートディレクトリにファイルを設置する
robots.txtとnoindexの違い
robots.txtと似た働きをするものに、「noindex」というメタタグを用いた設定があります。
似た働きをすることから、両者を混同してしまい、誤って使用してしまうケースが後を絶ちません。それは実際にGoogleも警告しているほどで、robots.txtとnoindexの混同はWebサイト運用において致命的な問題になりかねないため、両者についてしっかりとした理解が必要不可欠です。
noindexとは
noindexとは、指定したページを検索エンジンにインデックスされないよう指示するHMTLの記述を指します。ページの<head>内にメタタグでnoindexを記述し、インデックスから削除し、検索結果に表示されないよう命令できます。
robots.txtとnoindexの大きな違いは、robots.txtはクロールのみ制限することに対し、noindexは検索エンジンへのインデックス(登録)そのものをブロックすることです。そのためrobots.txtを実装したページは検索結果に表示される場合がありますが、noindexを実装したページが検索結果に表示されることはありません。
なお、Googleは以下の公式見解を示しています。したがって、検索結果に表示させないようにする目的でrobots.txtを使用しないようにしてください。
警告: robots.txt ファイルは、ウェブページを Google 検索結果に表示しないようにする目的で使用しないでください。説明テキストの付いたページは、他のページから参照されていれば、Google はクロールすることなしに URL をインデックス登録する可能性があります。検索結果にページを表示しないようにするには、パスワード保護やnoindexなどの他の方法を使用してください。
robots.txt の概要
また、robots.txtはテキスト以外に画像やCSSなどのファイルにも対応できますが、noindexは主にHTMLのみ対応します。
noindexの設定方法については、以下の記事で詳しく解説しています。
「5分で理解!noindexとは?設定方法やSEOにおける重要性について解説」
robots.txtとnoindexの使い分け方
では、robots.txtとnoindexをどのように使い分ければ良いのでしょうか。以下のような場面に応じて使い分けましょう。
<robots.txtを使うケース>
- クローラーに巡回してほしくないページをブロックし、効率的にクロールさせたい
- サイトへの過剰なリクエストによるオーバーロードを避けたい
「サイトへの過剰なリクエストによるオーバーロード」とはWebサイトへのアクセス数が増えることで、サイトへの負荷が大きくなることです。
<noindexを使うケース>
- サイトの価値を下げる低品質・重複コンテンツやテストページなど、検索結果に表示させたくないページがある
robots.txtの使用目的
robots.txtはWebサイトのページ、メディアファイル、リソースファイル(アプリケーションで使用する文字列データを定義するXMLファイル)などで使用します。ここではそれぞれの働きについて解説します。
Webページでの使用目的
Webページに対しては以下2つの目的で使用されます。
特定のページへのクロールを制限する
Webサイト内のSEOにおいて重要でないページ、あるいは類似したページのクロールを回避する目的で使用します。そのように使用することで、優先度の高いページへSEO評価を集めやすくなります。つまり優先度の高いページの順位上昇に寄与する可能性が高まります。
トラフィックを管理する
Googleなど検索エンジンのクローラーからのリクエストによってサーバーが過負荷になった場合、Webページにrobots.txtファイルを実装することでトラフィックを管理できます。
注意点
robots.txtは検索結果への表示を完全に避けることはできないことには注意しましょう。特定のWebページのURLを検索結果に表示されたくない場合は、noindexの使用やパスワード保護などで対応してください。
例えば、該当ページが他のページからリンクを貼られているなど参照を受けている場合、Googleなどの検索エンジンはクロールなしでインデックス登録する場合があります。
なおこのような場合、検索結果に表示されるのはページのURLのみで説明は表示されません。また画像・動画やPDFなどHTML以外のファイルも除外されますが、該当ページをブロックしているrobots.txtの記述を削除すれば修正できます。
メディアファイルでの使用方法
検索結果に画像・動画・音声などのファイルを表示させない目的で、robots.txtが設定されます。
なお、robots.txtファイルを設置して検索結果に表示されない場合でも、ユーザーがそのページを閲覧することは可能です。
リソースファイルでの使用方法
リソースファイルをブロックする目的でも、robots.txtが設定されます。
画像やJavaScript、PHP、Perlなどのスクリプト、CSSなどのファイルのブロックが可能です。
ただし、リソースファイルがないとクローラーがページの内容を把握しにくい場合、リソースをブロックすると相互リンクしているページを検索エンジンが巡回しにくくなるので避けてください。
robots.txtのSEO効果
ECサイトなど大規模なWebサイトには、「お問い合わせページ」や「PHPなどのスクリプト」など、SEOには重要ではないファイルが数多く存在するため、逆にSEO的に重要なページに対してクローラーが効率的に巡回できず、クローラビリティが下がる恐れがあります。
robots.txtでそれらのページへのクロールを制限すれば、SEO的に要なページが優先的に巡回され、結果的に検索結果上で「掲載順位への反映が早くなる」効果が期待できます。
ただし、そもそもページ数が少ない小規模なサイトでは、クロールを制限する必要がないため、大きなSEO効果は見込めません。
robots.txtの作り方
robots.txtの使い方やSEO効果がわかったところで、作り方・準備の仕方についてみていきましょう。
robots.txtを作る手順は以下の4ステップです。(具体的なrobots.txtの記述内容については、次の章で解説します。)
- 「メモ帳」「メモ」などのアプリを起動
パソコンにデフォルトで入っている「メモ帳」「メモ」など、テキストファイルを作成できるアプリを起動します。
↓ - ファイル名をつけて保存後にアップロード
ファイルを「robots.txt」という名前で保存し、サーバーにアクセスします。使用したいWebサイトのルートディレクトリ(TOPページが置かれた最上位の階層)にファイルをアップロードします。
↓ - 「robots.txt」ファイルに内容を記述
クローラーへの指示に応じて正しい内容を記述します。(記述内容については下記で紹介)
↓ - ファイルの内容が正しく動作しているかテストする
Googleサーチコンソールの「robots.txtテスターツール」で、指定したURLに対してクローラーをブロックできているか確認します。
続いて、robots.txtファイルの書き方について、情報として必要になる4つの要素と一緒に解説します。
robots.txtの書き方:4つの要素
robot.txtファイルには、次の4つの要素を用いてテキストファイルに記述する必要があります。つまり、robot.txtファイルの書き方は、この要素がどんな働きなのかを知ることで学ぶことができます。まずはざっくりとそれぞれの働きを見ていきましょう。
- User-Agent
- Disallow
- Allow
- Sitemap
| 要 素 | 働 き |
|---|---|
| User-Agent | 制御するクローラーの指定 |
| Disallow | クロールを禁止するディレクトリやページを記入 |
| Allow | クロールを許可するディレクトリやページを記入 |
| Sitemap | クローラーにSitemapの場所を伝える |
それぞれの働きや書き方について、さらに詳しく見ていきます。
User-Agent
User-Agentはrobots.txtを適用するクローラーの種類を指定する要素です。
<基本の記述>
User-Agent: ○○○○
※Googleにより「:」の後に半角スペースを入れることが推奨されています。「○○○○」の部分に対象となる制御したいクローラーの名称(たとえば、Googlebot)を書いて指定します。
クローラーはGooglebot(Google)、Bingbot(Microsoft)、Applebot(Apple)など多数存在します。またGoogleではGooglebot以外に、画像検索用のGooglebot-Image、モバイル検索用のGooglebot-Mobileなどもあります。どのクローラーを制御するのか確認してから記述しましょう。
<主な使い方>
・全てのクローラーを制御する場合
User-Agent: *
Googlebot(Google)だけでなく、Bingbot(Microsoft)、Applebot(Apple)といった、検索エンジンのあらゆるクローラーを制御の対象としたい場合は、「User-Agent: 」の後ろに「*」(アスタリスク)を記述します。
・特定のクローラー(例 Googlebot)を制御する場合
User-Agent: Googlebot
・複数、かつ特定のクローラーを制御する場合
User-Agent: Googlebot-Image
Disallow: /
User-Agent: bingbot
Disallow: /
User-Agentは1行につき1つしか指定できないため、2つ以上のクローラーを対象とする場合はそれぞれ記述してください。上記はGoogle画像検索とBing検索のクローラーを指定して、「Disallow:クロールを禁止する」場合です。なお、Disallowに関しては次の項目で説明します。
※4要素を記述する際に大文字・小文字の区別はなく、例えば「user-agent」と書いてもクローラーには通じます。ただ可読性や保守性を高めるためには、表記を統一することをお勧めします。
Disallow
Disallowは対象となるクローラーのクロールを禁止するディレクトリやページを指定する要素で、User-Agentと共に記述します。
<基本の記述>
User-Agent: *
Disallow: /○○
○○の部分に「URLパス(最上位のドメイン名に続く情報の文字列)」または「URLパスの先頭」を記述して、対象ディレクトリやファイルへのクロールを制限します。なお、Disallowを用いる場合は、先頭に「/」をつけます。具体例を見ていきましょう。
<主な使い方>
・すべてのクローラーに対して、Webサイト全体(すべてのURL)のクロールを禁止する場合
User-Agent: *
Disallow: /
「Disallow: 」の後に「/」を記述します。「/」の後ろには何も記述しないことで、サイト全体を指定することができます。
・Microsoftの検索エンジンbingのクローラー「bingbot」に対して、特定のディレクトリとその配下のページ全体を禁止する場合
User-Agent: Bing-bot
Disallow: /example/
「Disallow: /」の後にディレクトリ名(例:example)と「/」を記述し、「/example/」以下のページすべてを対象にしてクロールを禁止します。たとえば、以下のようなページへのクロールが禁止されます。
- https://example.com/example/
- https://example.com/example/sample.html
- https://example.com/example/sample-123.html
- https://example.com/example/sample/example-sample.html
・すべてのクローラーに対して、特定のページ(URL)のみ禁止する場合
User-Agent: *
Disallow: /example/sample.html
「Disallow: /」の後にページ名(例:example/sample.html)を記述します。これにより「/example/sample.html」へのクロールは禁止されますが、他のページは巡回されます。
・すべてのクローラーに対して、特定のファイル形式を禁止する場合:例).jpgファイルを制限
User-Agent: *
Disallow: /*.jpg$
「Disallow: 」の後に「/*」とファイル拡張子名(この場合は.jpg)を続け、最後に「$」を記述します。
なお、AllowやDisallowでは、正規表現を使ってURLパスを指定することが可能です。上記で紹介した「*」や「$」がその正規表現の文字(メタ文字)です。
「*」は0字以上の有効な文字
「$」はURLの末尾であることを指定
つまり、「/*.jpg」であれば、以下が該当しますが、
- /index.jpg
- /filename.jpg
- /folder/filename.jpg
- /folder/filename.jpg?parameters
「/*.jpg$」であれば、以下のみになります。
- /index.jpg
- /filename.jpg
- /folder/filename.jpg
したがって、クエリパラメーターなども含めてjpgファイルをクロール禁止にしたい場合は、「$」を外して以下のように書けばよいわけです。
User-Agent: *
Disallow: /*.jpg
robots.txtの正規表現については、Googleの公式ページでも解説されていますので、詳しく知りたい方は以下を参考にしてみてください。
「Google による robots.txt の指定の解釈」
・パラメータを含むページ(URL)を制限する場合
User-Agent: *
Disallow: /*?
「/*」でサイト全体のURLを指定、さらに「?」を記述することで、パラメータ付きのURLが指定されます。(URLにパラメータが付与される場合、必ず「?」が付くため)
※パラメータとはソフトウェアやシステムの挙動に影響を与える、外部から投入されるデータなどのことです。パラメータを含むURLはクローラーに重複コンテンツと認識される恐れがあるため、「/*?」を指定しパラメータが含まれるURL全てに対してのクロールを禁止することがあります。
Allow
Allowはクロールを許可する要素ですが、robots.txtはデフォルトでクロールを許可しているため、Allowを使う機会はあまりありません。ただし、既に「Disallow」を使っているディレクトリで一部だけクロールさせたい時は必要になります。
<基本の記述>
User-Agent: *
Disallow: /○○○
Allow: /○○○/△△/
「Allow: 」以下に、クロールを許可するディレクトリやページのURLパスを記述します。
<主な使い方>
・クロールを禁止したディレクトリの下に、クロールさせたいディレクトリやファイルがある場合
User-Agent: *
Disallow: /example/
Allow: /example/example-sample/
Sitemap
xml形式のサイトマップの存在を検索エンジンに知らせる要素です。xml形式のサイトマップとは、Webサイトの構造や各ページの情報を検索エンジンのクローラーに伝えるファイルです。Webサイト上に設置されるHTMLで書かれたページとは別である点には注意が必要です。
xmlサイトマップは設定しなくても問題はありませんが、記述した方がSEOには効果的です。サイトマップが複数ある場合は改行してください。
<基本の記述>
User-Agent: *
Sitemap: ○○○○
※xml形式のサイトマップが設置されているURLを「○○○○」にそのまま記入します。なお、サイトマップは、複数指定することができます。次の行に並べるようにして、指定しましょう。
User-Agent: *
Sitemap: ○○○○
Sitemap: ▼▼▼▼
<主な使い方>
・すべてのクローラーに対して、特定のページ(URL)のみクロールを禁止しつつ、サイトマップの場所を知らせる場合
User-Agent: *
Disallow: /example/sample.html
Sitemap: http://example.com/sitemap.xml
robots.txtの動作確認方法
robots.txtが正しく記述・動作していなければクロール制限の効果は期待できません。それどころか記述ミスをすると、本来クロールしてほしかったディレクトリやファイルがブロックされるなど、Webサイトに悪影響が及ぶ恐れもあります。
そこで必要になるのが記述や動作の確認です。確認には「Googleサーチコンソール」に搭載されている「robots.txtテスター」を使いましょう。
確認の手順は次の通りです。
①robots.txtテスターにアクセスする
robots.txtテスターには、このURLからアクセスしましょう。以前、robots.txtテスターはGoogleサーチコンソールからアクセスできましたが、現在サーチコンソールが新しくなったため、いまのところ実装されていません。そのため、上記のURLから直接アクセスするか、Googleで「robots txt テスター」と検索してアクセスしましょう。
②表示画面内に作成したrobots.txt構文をペースト
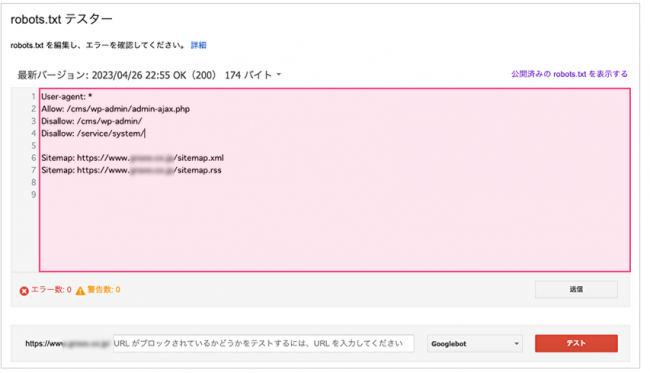
③画面最下部のスペースに該当するディレクトリ名・URLを記述し、「テスト」をクリック
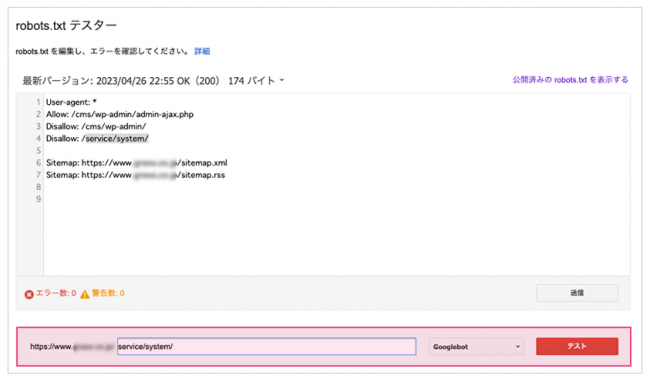
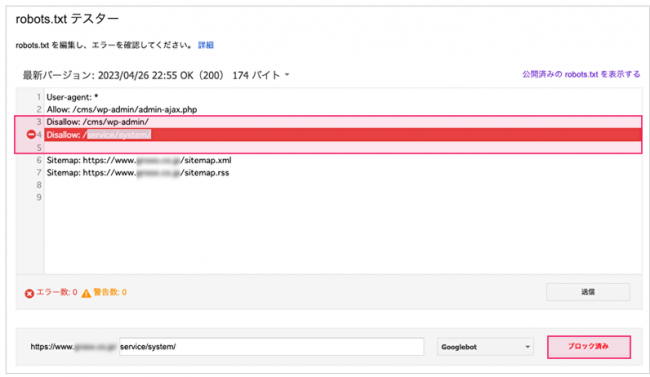
④Disallowで記述した箇所が赤く表示され、「ブロック済み」と表示されるか確認
robots.txtの設定方法
正しい動作が確認できたら、FTPソフトを使用しWebサイトにファイルをアップロードしましょう。クローラーが正しく読み込めるよう、ファイル名は必ず「robots.txt」にしてください。
Webサイトのルートディレクトリ以外の場所に設置すると効果がありませんのでご注意ください。
<記入例>
- 〇 https://example.com/robots.txt
- × https://example.com/sample/robots.txt
robots.txtを活用する上での注意点
本章では、robots.txtを使う上で必ず知っておきたい5つの注意点について紹介します。
- robots.txtを設置してもユーザーは閲覧できる
- robots.txtの内容が反映されるまで一定の時間がかかる
- robots.txtルールに対応しない検索エンジンもある
- 構文の解釈はクローラーによって異なる
- robots.txtで制限してもインデックスに登録され得る
robots.txtを設置してもユーザーは閲覧できる
robots.txtを設置しても、検索結果に表示される可能性があり、また、サイト内のリンクや外部リンクからアクセスすることができるため、ユーザーは閲覧できます。ユーザーに閲覧してほしくないページにはrobots.txtではなくnoindexを使用するか、ページを削除するようにしましょう。
ただしrobots.txtでクロールを制限しているページにnoindexを設置しても、インデックスを拒否する命令は伝わりません。その場合はまず該当ページからrobots.txtの指定を外してクロール制限を解除してから、noindexを設定し、その後でrobots.txtを設定してください。
robots.txtの内容が反映されるまで一定の時間がかかる
robots.txtファイルのアップロード後、内容が反映されるまで一定の時間(7~14日程度)がかかります。すぐに結果が表れるわけではないことを認識しておきましょう。
robots.txtルールに対応しない検索エンジンもある
Googlebotなど検索エンジンのクローラーのほとんどはrobots.txtの指示に従いますが、なかには対応しない検索エンジンもあります。全ての検索エンジンのクロールを制限するには、該当ファイルをパスワードで保護するなど他の方法で対応してください。
構文の解釈はクローラーによって異なる
多くの検索エンジンのクローラーはrobots.txtファイルのルールに従いますが、ルールの解釈は各クローラーで異なります。クローラーによっては指示が理解されないケースもあるため、適切な構文の記述を意識してください。
robots.txtで制限してもインデックスに登録され得る
Googleはrobots.txtで制限されたページのクロールやインデックス登録を行いませんが、制限の対象になっているURLが他からリンクされている場合、そのつながりをたどってインデックス登録する可能性があります。
そのためクロール制限したURLアドレス、または制限したファイルのアンカーテキストなど、その他の情報がGoogleの検索結果に表示されることがあります。
Google検索へのURL表示を防ぐにはサーバー上で該当ファイルをパスワード保護する、あるいはnoindexを設定するなどの方法で対応してください。

まとめ
今回はrobots.txtの概要やSEOにおける効果、設定方法などについて解説しました。
robots.txtの主な機能は以下の通りです。
- 特定のディレクトリやページ、メディアファイルのクロールを制限(禁止)できる
- サイトマップを指定することができる
これらの働きを適切に使えば、特定のディレクトリやページ、ファイルを優先的にインデックスさせ、SEO効果を高めることにつながります。robots.txtの作成方法や書き方については、本文で詳しく解説していますので、参考にしてみてください。
robots.txtの設定にあたっては次の5つのポイントに注意しましょう。
- robots.txtを設置してもユーザーは閲覧できる
- 反映まで一定の時間がかかる
- robots.txt ルールに対応しない検索エンジンもある
- 構文の解釈がクローラーによって異なる
- robots.txtを設定してもインデックスに登録され得る
注意すべきポイントはいくつかありますが、「robots.txt」はSEO対策に良い影響を与える方法です。SEO対策に課題を抱えている方は、ぜひrobots.txtの設定に取り組んでみてください。
詳しくはこちら










Keywordmapのカスタマーレビュー
ツールは使いやすく、コンサルタントのサポートが手厚い
良いポイント
初心者でも確実な成果につながります。サポートも充実!
良いポイント
機能が豊富で、ユーザーニーズ調査から競合分析まで使える
良いポイント