Webサイトの集客改善について、”無料”で相談してみませんか?
貴社に最適なSEO対策・コンテンツ制作・リスティング広告運用を無料でアドバイスいたします!
▶無料のSEO相談窓口はこちらから
クローリングとは?SEOになぜクローラー対策が重要なのか

また、Keywordmapを開発したCINCでは、ビッグデータを活用し、SEO戦略の策定から効果検証まで一気通貫で支援しています。SEOに詳しい人がいない、Webサイトの集客数を増やしたいといったお悩みがある方はお気軽にご相談ください。⇒CINCのSEOコンサルティング・SEO対策代行サービス
目次
クローリングとは
まず、「クローラー」「クローリング」とはどのようなものか、基本から説明していきます。
クローリングの定義
ひとことで言えば、クローリングとは、Web領域においてプログラムを用いることで、Webページの情報を収集する手法です。
クローリングとはどのようなものか定義がweblioに掲載されているので、そちらの内容を引用して紹介します。
▼weblio定義
クローリングとは、ロボット型検索エンジンにおいて、プログラムがインターネット上のリンクを辿ってWebサイトを巡回し、Webページ上の情報を複製・保存することである。クローリングを行うためのプログラムは特に「クローラ」あるいは「スパイダー」と呼ばれている。クローラが複製したデータは、検索エンジンのデータベースに追加される。クローラが定期的にクローリングを行うことで、検索エンジンはWebページに追加・更新された情報も検索することが可能になっている。(参照:https://www.weblio.jp/content/クローリング)
上記の内容がクローリングの定義となりますが、やや難しい表現となっているので、噛み砕いて説明していきます。
クローリング=巡回と情報収集
まず、ロボット型検索エンジンという言葉ですが、こちらはGoogleやYahooなどの検索エンジンが保有する技術となります。またGoogleやYahooがクローリングを行うロボットをクローラーと呼びます。
リンクからリンクへと移動することで、Webサイト上の無数にあるページ情報を収集するプログラミングをクローラーに施し、Webページの情報を収集しているのです。
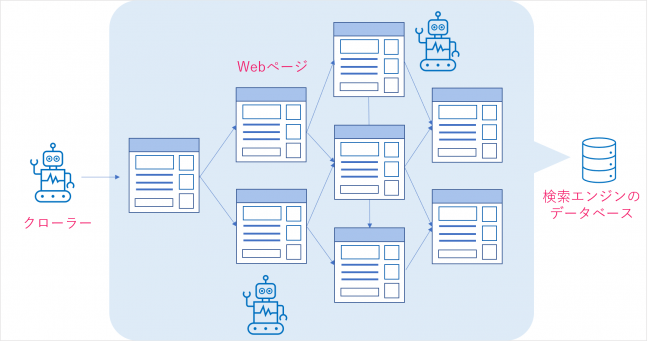
クローリングによって集めたページ情報はデータベースに保管されます。
ここによく勘違いされやすい点があります。クローリングはページ情報の収集とデータベースへの保管までが役割であって、検索結果に表示させるかどうかが決まるindex有無や、検索順位の決定に影響するものではありません。注意しましょう。
なお、詳しくは下記で解説しますが、クローリングはGoogleやYahooといった検索エンジン固有の技術ではなく、様々なWebサイトやツールでも同様の技術が活用されています。
クローリングとスクレイピングの違いについて
クローリングと同義であると間違いやすい言葉としてスクレイピングが存在します。
スクレイピングはクローリングによって収集したページ情報(HTMLデータ)を抽出し、加工する技術となります。
クローリングでデータを収集した後に、収集したページ情報(HTMLデータ)を加工する作業と認識して、クローリングと混同しないようにしましょう。
クローラーとクローラビリティ
クローラーは検索エンジンやウェブサイトがクローリングを行うためにプログラミングを施した「ロボット」です。このロボットがページの情報を収集して、収集したデータをデータベースに保管します。
クローラーの代表例はGoogleが保有するGooglebotです。GooglebotはSEOを行う上で、非常に重要なクローラーとなります。
また、クローリング、クローラーと並んでクローラビリティという言葉もサイト運営者は耳にしたことがあるかと思います。
クローラビリティは検索エンジンやwebサイトが保有する技術ではなく、サイト運営者が検索結果に表示させたいページをクローラーに回遊させるために、クローラーを評価させたいページに誘導させる戦術になります。したがって、SEOに含まれるひとつの施策と捉えて問題ありません。
クローラーの活用は検索エンジン以外でも存在
前文で少し触れましたが、クローリングは検索エンジンだけでなくWebサイトの運営会社も保有する技術になりつつあります。
クローリング技術を保有してWebサイトに活用するサイトは、アグリゲーションサイトと呼ばれています。アグリゲーションサイトは、膨大な数存在するWebサイトにおいて展開されているページ情報をクローリングで収集し、自社のデータベースに保管するまでは検索エンジンと同様です。
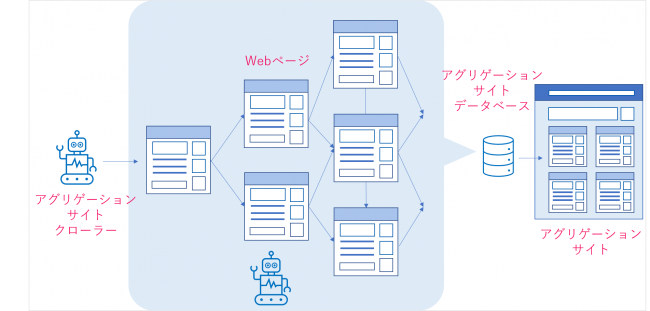
しかし、アグリゲーションサイトは検索エンジンとは異なり、目的となるテーマに関するページ情報を収集し、かつ保管したデータを運営するサイト(アグリゲーションサイト)のページ情報として掲載します。
こういったアグリゲーションサイトの代表例が求人サイトのIndeedや旅行サイトの「トラベルコ」などが挙げられます。
なぜクローリングは重要なのか?
ここでは、クローリングがなぜ重要なのかについて、サイト運営者側の立場から解説します。
一言でいえば、集客のためです。
基本的に、クローリングはサイト上のあらゆるページの情報を収集することが可能であり、かつサイトに存在する大半のページの情報を収集可能です。このようなクローリングを受けるサイト運営者側のメリットは、検索結果でWebサイト・ページを表示させることです。たとえばGoogleの検索結果(それも高順位)に表示させることができれば、キーワードの検索回数次第では、膨大な数のユーザーを、自社や自社プロダクトを紹介するページに呼び込む集客窓口になり得ます。
つまり、クローリングそのもの、およびクローリングについての理解、集客において非常に重要なのです。
しかしながら、ここでポイントになるのは、クローラーが収集するページの順番などは、サイト運営者がアクションを起こさないとコントロールできない点です。後半の章で詳しく紹介しますが、サイト運営者はXMLサイトマップやサーチコンソールを活用して、クローラーに優先的に検索結果に表示させたいページを読み込ませるように努めます。クローリング対策がSEOで有効とされる理由は、優先的に読み込ませたいページをクローラーに伝えることが、サイト運営者から可能なためです。
クローラーの特徴について
さて、クローリングについて理解したところで、実際に我々が触れるクローラーとはどのような特徴があるのかについて説明していきます。
クローラーの種類
先述で、クローラーには検索エンジンが保有するクローラーとサイトが保有するクローラーの2種類が存在すると説明しましたが、ここではGooglebot以外のクローラーも取り上げます。
Googlebot
Googleが保有する、ページ情報を収集するクローラーで、収集した情報をデータベースに保管する役割を持つ。GooglebotはGoogleの保有するメインのクローラだが、他にも目的別、デバイス別に以下のようなプログラムが稼働している。
- 画像用:Googlebot-Image
- 動画用:Googlebot-Video
- ニュース用:Googlebot-News
詳しくは、Google検索セントラルのGoogleクローラの概要(ユーザーエージェント)で解説されている。
※なおYahoo!検索だが、Googleの検索エンジンを採用しているため、当然、クローラもGooglebotが使われている。余談だが、国内の検索エンジンの利用率はGoogleとYahoo!を合わせて96%ほどを占めているため、SEOを行う対象としてはGoogleを基準とすればよいだろう。
Bingbot
Microsoft Bingが保有するページ情報の収集をするクローラーで収集した情報をデータベースに保管する役割を持つ。
Indeedのクローラー
正式名称は不明だが、Indeedが保有するクローラーで、収集した情報をデータベースに保管する役割を持つ。Indeed以外にも様々なWebサイトで同様のクローラーが用いられていると考えられる。
検索エンジンが保有するクローラーもアグリゲーションサイトが保有するクローラーもクローラーの役割は同じくページ情報の収集となります。
クローラーが閲覧できるファイル
クローラーはHTML、CSS、PDF、PHP、Javascript、あるいは画像、動画など様々なファイルの情報を収集できます。
一方で、SEOを意識する場合には、クローラーにHTMLのデータでページを読み込んでもらうことが重要になります。実際の検索結果を見るとわかりますが、検索結果に表示されるページの大半はHTML、および画像、動画です。
なぜこれらなのかというと、検索エンジンが保有する検索アルゴリズム※が、HTMLや画像などのデータを高く評価するためです(高く評価するのは、実際にユーザーが目にするファイルであるため)。
※検索アルゴリズムは、検索結果に表示するかの判断に加え、表示させる検索キーワードとその場合の検索順位を決定する技術です。
またアグリゲーションサイトであるIndeedのクローラーは、そもそもHTMLのデータしか収集しません。そのため、検索結果への表示、アグリゲーションサイトへの表示という観点でも、基本的にHTMLでWebページを構成することが有効になります。
クローリング対策とは
クローリング対策はSEOにおける重要な施策であり、検索結果に表示させたいページを優先的にクローラーに回遊させるのがポイントだと説明しました。
この章では、クローラーの情報収集から検索結果に表示されるまでのメカニズムや、サイト運営者が行う代表的なクローリング対策であるサーチコンソールのURL検査やXMLサイトマップの手法を紹介します。
クローラーにページ情報を収集させることが、インデックスの第一段階
SEO対策として検索結果に表示される(インデックスされる)までのメカニズムについて簡単に説明します。なお、詳しくは「検索エンジンの仕組みを解説!その他検索機能や重要アルゴリズムも紹介」をご覧ください。
検索結果に表示されるまでのメカニズム
- クローラーがWebサイトを巡り、ページ情報を収集する
- クローラーが収集したページ情報をデータベースに保管する
- 検索アルゴリズムがデータベースにあるページ内容を確認して、検索結果に表示させるべきかどうかを判断する
上記が検索結果に表示されるまでのメカニズムになります。
したがって、サイト運営者は検索結果に表示させたいページを回遊させるクローリング対策と同時に、検索アルゴリズムに評価されるページ作成も重要な要素となります。ここでは、クローリング対策、つまりクローラビリティを高めるための、具体的な対策方法について以下で解説します。
クローリング対策でユーザーがサイト管理者が行うべき対策
原則的にクローラーはサイトの上部階層から入り、サイト内のリンクを辿りながらページの情報を収集していきます。つまりサイトの上部階層にあたるTOPページを中心にクローリングを始め、サイト内のリンクを辿って、クローリングが許可されているあらゆるページの情報を収集することになります。
サイト内のリンクは別名、内部リンクと呼ばれることもあります。この内部リンクを辿る特性を活かして、クローリング対策としては検索結果に表示させたいページの優先順位を、上部階層で設計しているWebサイトが多い傾向にあります。
ただ、この方法は基本的に受動的であり、クローラーの訪問を待つことが前提となります。一方で、クローラーの訪問を促す方法も存在します。
クローリング対策
では、クローリングを促すためにできること、すべきことを具体的に見ていきましょう。以下の3点となります。
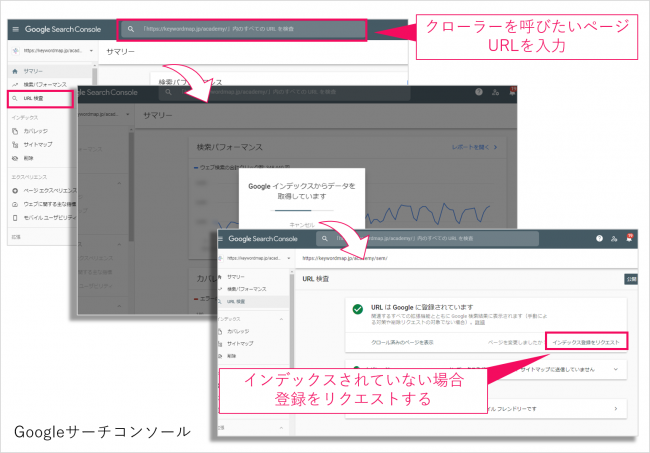
URL検査(能動的にクローラーを呼び込む)
新しく作成したページや早期に検索結果に表示させたいページが存在する場合には、GoogleサーチコンソールのURL検査の活用を推奨します。
URL検査で対象のページについて「インデックス登録をリクエスト」することで、確実にGoogleのクローラーが回遊し情報を収集することになります。ただ、URL検査には注意点もあり、1ページ毎の登録になるため複数ページを登録することには不向きになります。多数のページをまとめてクローラーにインデックスを促したい場合は、下記で紹介するXMLサイトマップ(sitemap.xml)をGoogleに伝える必要があります。
XMLサイトマップ(sitemap.xml)の生成
XMLサイトマップ(sitemap.xml)を利用することで、クローラーに優先的に閲覧させたいページをサイト管理者が検索エンジン側に伝えることができます。
XMLサイトマップとはXML形式のファイルであり、ユーザーにサイト構造を伝える案内図として機能する、リンクを掲載したサイトマップのGoogle版です。XMLサイトマップには、サイト上のページIRLや更新日時などが記述されており、Googleはこれを参考にしてWebサイトをクローリングします。
作成したXMLサイトマップは、一般的にWebサイトのトップディレクトリにアップロードしておきますが、URL検査とは別に、サーチコンソール上で送信することもできます。作成にやや時間が掛かりますが(無料のツールを使えば瞬時に作成可能)、最大5万ページ(50MB)までの情報を送信できるため、URL検査と異なり複数ページのクローリング対策に有効です。
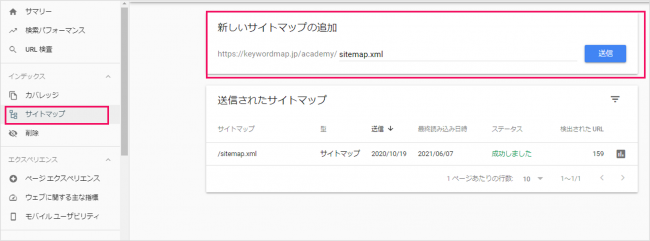
なおXMLサイトマップを伝えるには、robots.txt※に挿入してサイトマップの格納場所を指定するパスを記載する方法もあります。Googleだけであれば、サーチコンソールだけでも構わないのですが、他の検索エンジンにも伝えたいのであれば、この方法が確実です。XMLサイトマップをサーチコンソールのサイトマップ欄より登録を行って、サイトマップの送信が完了します。
※robotos.txtとは、クローラーに閲覧されたくない部分をクロールされないように制御するファイルのことです。Webサイトのルートディレクトリに設置します。
クローリングを拒否する
ここまではクローリングを促す方法について解説しましたが、一方であえてクローリングを拒絶する必要があるケースも存在することを覚えておきましょう。
例えば、画像が動画など、サイズが膨大なファイルがクロールされると、サーバーへの負荷が大きくなってしまうため、クローリングを拒否する場合があります。同時に、優先順位の高いページをなるべく早くクローリングしてもらうために、robot.txtを使ってクローリングを制御することもあります。
クローリングを拒否するためには、先ほども説明したように、robots.txtというテキストファイルを作成します。
記述方法は、初めに「User-agent:クローラー名」と書きます。
例)
- User-agent:Googlebot
続いて「Disallow:拒否したいURL(もしくはファイル名)」という形式で記述していきます。
例)
- Disallow:/movies/
- Disallow:/movies/○○mp4

まとめ
クローリング・クローラー・クローラビリティについて紹介しました。
クローリング対策はSEOとして、非常に有効な手段です。URL検査やXMLサイトマップも活用して、多くのページを検索結果に表示するようにしてみてください。
また、クローリング対策同様にSEOとして検索アルゴリズムに適応するページ作成も重要です。ページ作成を行う際には、まず第一に良質なコンテンツ、そしてサイトとコンテンツの関連性、タイトルやhタグ、ページ内のキーワードが検索結果への表示や検索順位に影響してきます。
クローラビリティを高めることでGoogleに親切であり、かつコンテンツの品質を担保することでユーザーの便益を最大化する、この相乗効果でSEOは成功に近づきます。
詳しくはこちら










Keywordmapのカスタマーレビュー
ツールは使いやすく、コンサルタントのサポートが手厚い
良いポイント
初心者でも確実な成果につながります。サポートも充実!
良いポイント
機能が豊富で、ユーザーニーズ調査から競合分析まで使える
良いポイント